Cheap and reproducible testing environments on AWS
Giorgio Sironi
If you are looking at these slides on your pc, there are speaker notes in the HTML
Giorgio Sironi (@giorgiosironi)



Giorgio Sironi
If you are looking at these slides on your pc, there are speaker notes in the HTML
Giorgio Sironi (@giorgiosironi)





| Server-based resources | Shared resources |
| Web servers, databases | Queues, CDNs, ... |
| EC2, RDS, ElastiCache | S3, SQS, CloudFront |
| Pay by the hour | Pay per use |
| Optimize | Don't worry about it |
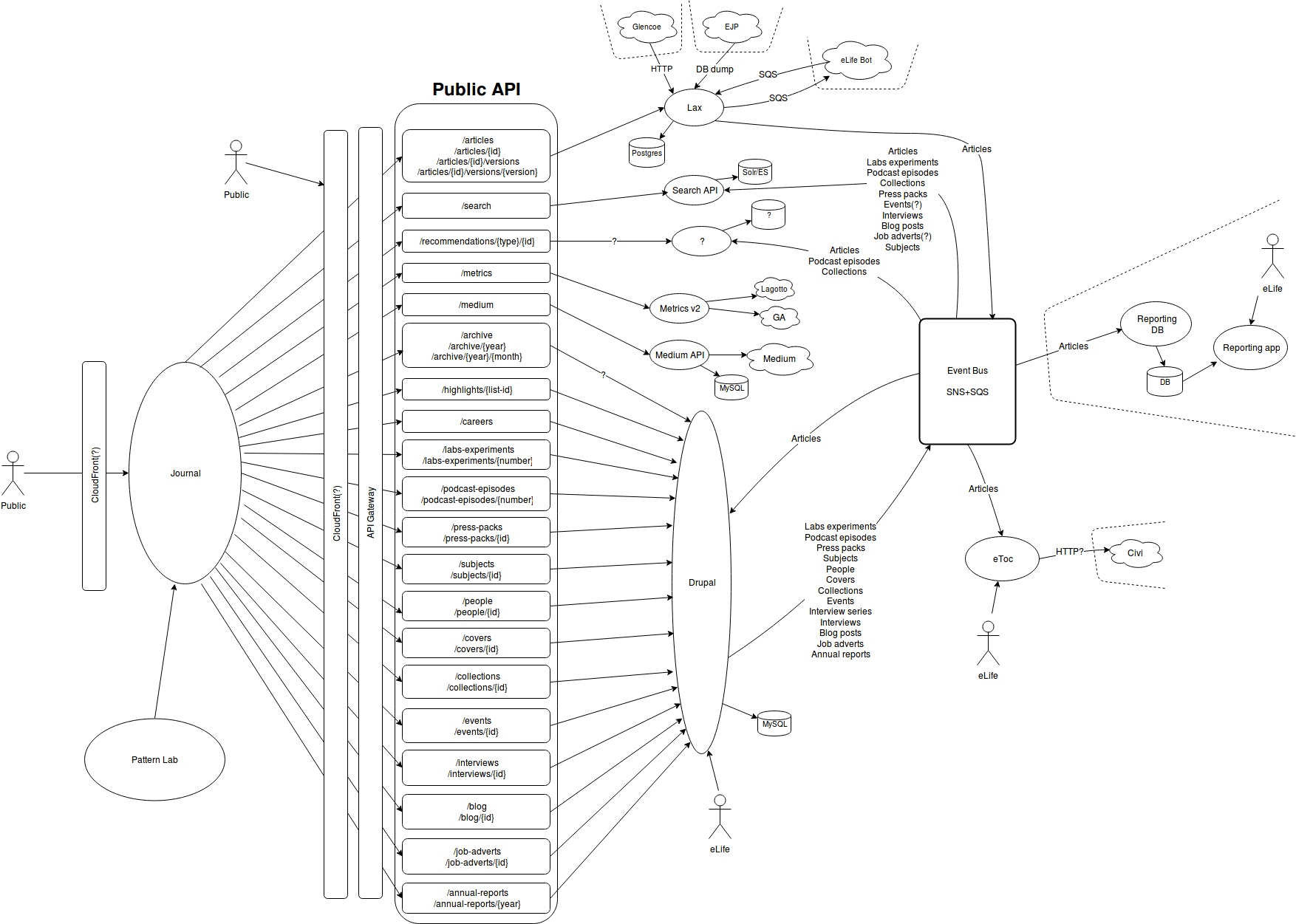
 You may want to build EC2 instances from scratch starting from an AMI, or even to dynamically instantiate a CloudFormation template when you need it. However, the overhead of provisioning new resources is still significant for test suites. You may have a test suite that takes 5 (single project) or 20 (end2end) minutes to run. It's not efficient to create everything from scratch whenever you need it, as for some resources you only pay for usage and there are lots of things that can go wrong during the initial creation.
For example, to provision a CloudFront CDN for end2end tests, it takes ~1 hour. However you only pay for the data actually transferred through it. And you don't want to wait 1 hour to find out the DNS name is conflicting with something else and the creation is rolled back.
You may want to build EC2 instances from scratch starting from an AMI, or even to dynamically instantiate a CloudFormation template when you need it. However, the overhead of provisioning new resources is still significant for test suites. You may have a test suite that takes 5 (single project) or 20 (end2end) minutes to run. It's not efficient to create everything from scratch whenever you need it, as for some resources you only pay for usage and there are lots of things that can go wrong during the initial creation.
For example, to provision a CloudFront CDN for end2end tests, it takes ~1 hour. However you only pay for the data actually transferred through it. And you don't want to wait 1 hour to find out the DNS name is conflicting with something else and the creation is rolled back.
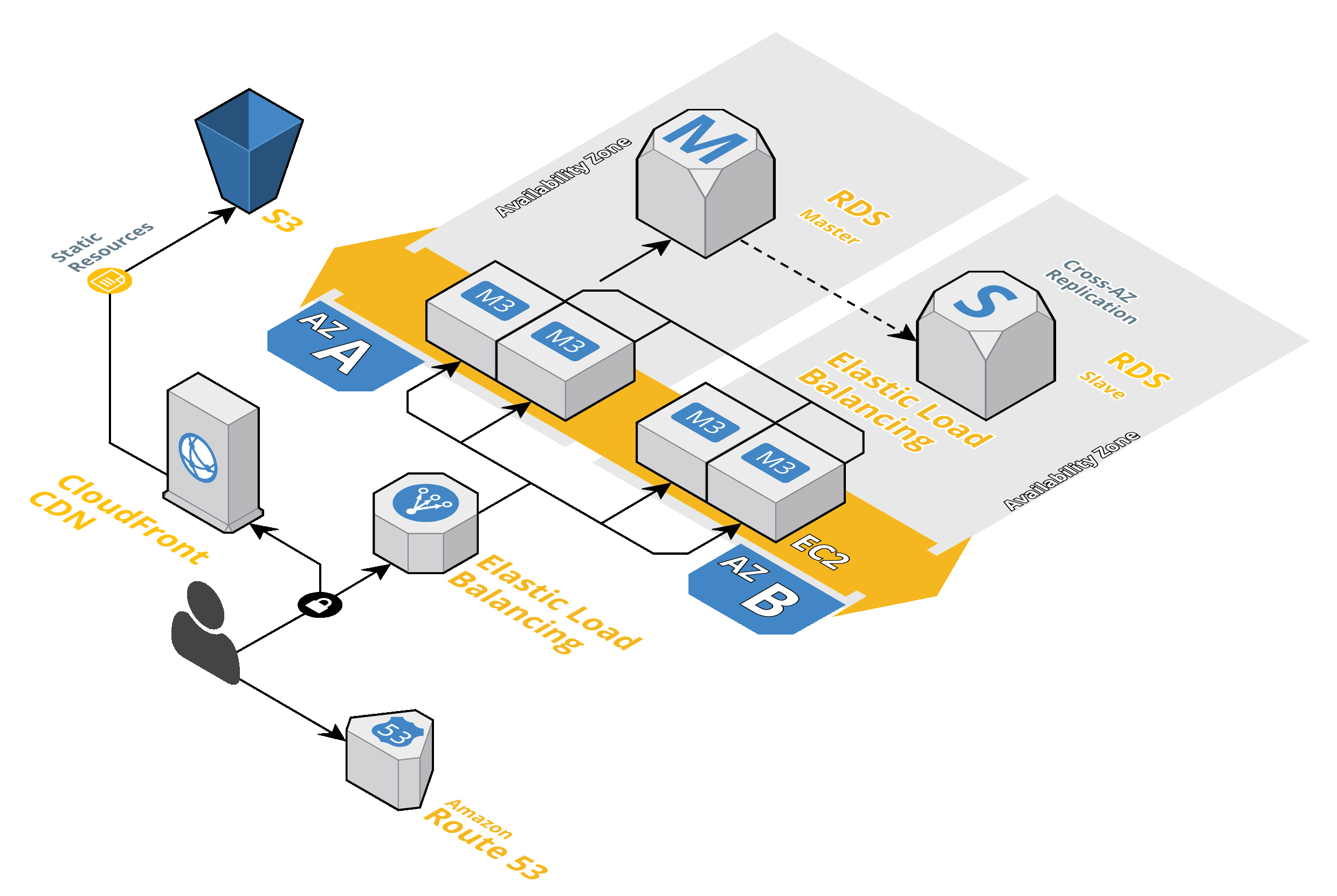
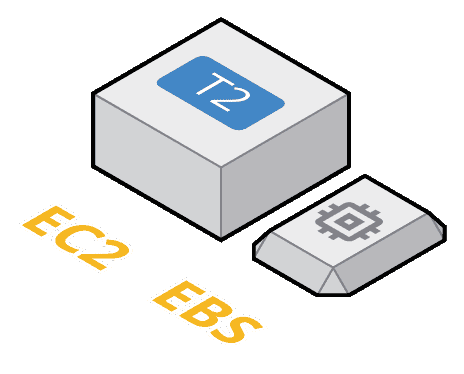 Here is a typical EC2 instance for one of our project. For general purpose instances, EC2 has moved away almost everywhere from instance-backed store, which is ephemeral, to favor EBS. EBS is a block-oriented storage (think of /dev/sdX descriptors to mount) remote to the instance but located and replicated in the same data center. So good combination of low latency and durability. It can still fail, but it allows you to stop and start instances as you would with your laptop.
Here is a typical EC2 instance for one of our project. For general purpose instances, EC2 has moved away almost everywhere from instance-backed store, which is ephemeral, to favor EBS. EBS is a block-oriented storage (think of /dev/sdX descriptors to mount) remote to the instance but located and replicated in the same data center. So good combination of low latency and durability. It can still fail, but it allows you to stop and start instances as you would with your laptop.
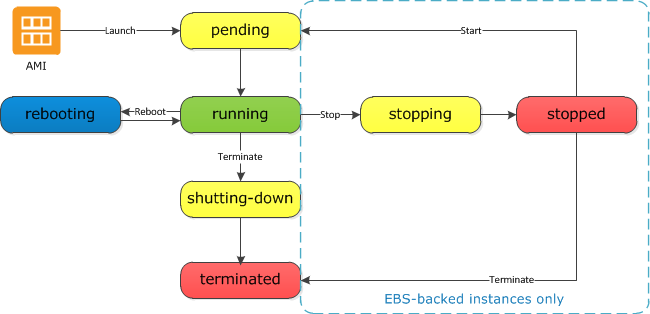 Since EC2 started relying on this SAN, in fact, it gained the "start" and "stop" API calls. Stop really means to free the physical server that was hosting the virtual machine by shutting it down; but the EBS for its / root volume remains around. Start means to find another physical server that has resources (CPU, RAM, bandwidth) to allocate the virtual machine persisted on the EBS.
Since EC2 started relying on this SAN, in fact, it gained the "start" and "stop" API calls. Stop really means to free the physical server that was hosting the virtual machine by shutting it down; but the EBS for its / root volume remains around. Start means to find another physical server that has resources (CPU, RAM, bandwidth) to allocate the virtual machine persisted on the EBS.
| t2.small | $0.74/day |
| t2.medium | $1.46/day |
| t2.large | $2.88/day |
| t2.xlarge | $5.86/day |
| c4.4xlarge | $23.93/day |
| SSD gp2, 10 GB | $1.20/month |

aws ec2 start-instances --instance-ids i-1234567890 // poll for started state: aws ec2 describe-instances --instance-id i-1234567890 // poll with ssh that you can connect // (optionally) poll for some smoke test to pass // update DNS with new public ipStopping an instance is easy, restarting it is more difficult. Actually I do this with Python, but I show it with the cli since it's universal.
aws ec2 stop-instances --instance-ids i-1234567890 // poll for stopped state: aws ec2 describe-instances --instance-ids i-1234567890
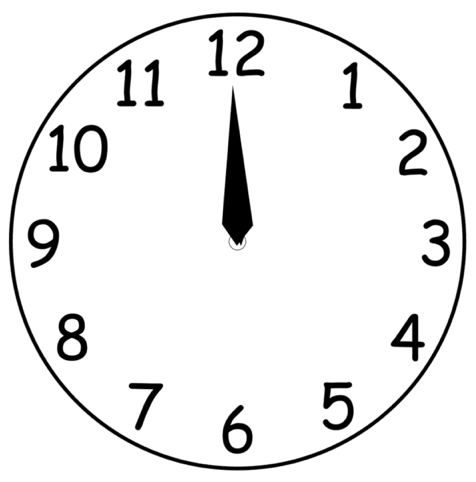 You stop paying as soon as the status changes from `running` to `stopping`.
More than stopping, the problem is knowing when to stop.
Periodical build that checks whether instances are between X:55 and X:60 minutes from start, leveraging the full hour that has been paid and stopping before they go into the next
Now changing that... it's billed minute by minute, so will probably shrink to anything more than 0:15? 0:30? So that if there are many builds in sequence they have the time to run.
You stop paying as soon as the status changes from `running` to `stopping`.
More than stopping, the problem is knowing when to stop.
Periodical build that checks whether instances are between X:55 and X:60 minutes from start, leveraging the full hour that has been paid and stopping before they go into the next
Now changing that... it's billed minute by minute, so will probably shrink to anything more than 0:15? 0:30? So that if there are many builds in sequence they have the time to run.
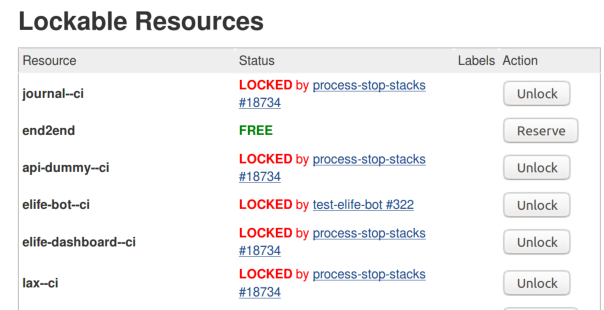 Starting and stopping instances periodically would be otherwise dangerous if there wasn't a mechanism for mutual exclusion between builds and lifecycle operations like starting and stopping. Not only you don't want to run builds for the same project on the same instance if they interfere with each other, but you definitely don't want an instance to be shutdown while a build is still running.
Therefore, we wrap both these lifecycle operations and builds in locks for resource, using Jenkins Lockable Resources plugin. If the periodical stopping task tries to stop an instance where the build is running, it will have to wait to acquire the lock. This ensures that machines that see many builds do not get easily stopped, while other ones that are idle will be stopped at the end of their already paid hour.
Starting and stopping instances periodically would be otherwise dangerous if there wasn't a mechanism for mutual exclusion between builds and lifecycle operations like starting and stopping. Not only you don't want to run builds for the same project on the same instance if they interfere with each other, but you definitely don't want an instance to be shutdown while a build is still running.
Therefore, we wrap both these lifecycle operations and builds in locks for resource, using Jenkins Lockable Resources plugin. If the periodical stopping task tries to stop an instance where the build is running, it will have to wait to acquire the lock. This ensures that machines that see many builds do not get easily stopped, while other ones that are idle will be stopped at the end of their already paid hour.

Error: InsufficientInstanceCapacity
![]()